Master the MapReduce programming model. Enroll today to get training from a MapReduce expert.
Course Duration
24 Hrs.Live Project
2 ProjectCertification Pass
GuaranteedTraining Format
Live Online /Self-Paced/ClassroomWatch Live Classes

Speciality
250+
Professionals Trained4+
Batches every month20+
Countries & Counting100+
Corporate Served- MapReduce is a licit programming model and an associated implementation for processing and initiating big data sets with a parallel, distributed algorithm on a cluster. In fact, you will find these specific applications scripting applications that can process huge amounts of data across the clusters of in-expensive nodes. Hadoop MapReduce is the processing part of Apache Hadoop. It is also referred as the heart of Hadoop.
- It is the most preferred data distilling application. Huge establishments like Amazon, Yahoo, Zuventus, etc. are utilizing the MapReduce platform for high volume data processing. In the present scenario, it is one of the most demanding courses in Big Data Hadoop field, and acquiring its accreditation will help you to uplift your career in various ways. And regarding it’s training Croma Campus would be the appropriate place for you.
- Things you will learn:
- Here, you will receive a detailed sort of training concerning several instances. Along with theoretical training, you will also be given practical training respectively.
Here, you will find a wide range of courses belonging from different industries.
Along with training, here, you will be able to acquire its prerequisites as well.
Our trainers will also give you the flexibility to acquire training via online/offline medium both.
We will also assure you 100% placement.
MapReduce Certification Training


- Croma Campus is immensely popular because of its exceptional offerings like high-quality training, placement offers. Moreover, it also makes you aware of its latest trends.
By enrolling in our certification program, you will get the opportunity to have a strong base knowledge concerning this subject.
In fact, our trainers will thoroughly guide you to the main concepts of MapReduce and Big Data, and their implementations.
Further, you will be explained the detailed information regarding the MapReduce framework.
You will also receive sessions regarding executing non-Java programs.
Moreover, utilization of HDFS will also get cleared.
- By acquiring this valuable accreditation, you will get a decent salary structure right from the beginning.
Post acquiring its minute details, you will always stand out differently from your peers.
You will receive immense respect from your colleagues, and senior officials.
Well, at the beginning your salary package will be around- 2,71,000-3,71,000 respectively, which is eventually good for starters.
With time and experience, your salary bracket will eventually get increased.
Moreover, you will also end up acquiring a higher place in your direction.
- Big Data Hadoop is one of the leading fields and has a bright scope ahead as well. Choosing this direction will only give you ample opportunities to acquire the latest facts and features concerning this technology.
By acquiring this important accreditation, you will be able to work as a Hadoop Administrator, Hadoop Developer, Machine Learning Engineer, Big Data Architect, and Big Data Consultant respectively.
There are different sorts of certifications as well. And our trainers will briefly tell you about that accreditation in detail.
By obtaining this accreditation along with higher-level certifications, you will be able to secure a much higher place in an organization.
You will also get the chance to lead the team and make business-driven decisions for your company.
Moreover, you will also get the opportunity to learn new things.
- There are several valid reasons to acquire this accreditation, and one of the significant ones is its high demand, and scope in the coming years.
It's quite a cost-effective way.
By learning its details, and features, you will be able to secure your applications with a different aspect.
Furthermore, you will be able to implement parallel processing respectively.
This specific technology is quite easy to handle, and with its simple structure, you will be able to execute your tasks smoothly.
By obtaining this accreditation in hand, you will be able to sustain yourself in this field in the long run.
- A MapReduce Programmer has to execute a lot of things. If you also aspire to turn into a good MapReduce Programmer, then you should know its duties beforehand.
You will have to execute the dataset across Mapper, and Reducer.
Your job role will also comprise of executing tasks on the slave node.
In fact, you will also have to handle Hadoop Distributed File System effectively.
Furthermore, you will also have to solve job requests from the clients.
In a way, you will have to understand the functioning of its numerous elements to come up with effective results respectively.
- Today many firms are always looking for MapReduce experts that can help them utilize the power of this magnificent programming model/ framework. This is why firms that use this framework for data processing don’t hesitate to give a decent amount of money to MapReduce experts who can help them use this framework without any difficulty.
- Top hiring companies for MapReduce professionals:
Impetus, Capgemini, TCS, Accenture, etc., are the top-most companies hiring skilled candidates.
Moreover, by graduating from our institution, you will be able to get settled in this direction easily.
In fact, you will end up grabbing a good decent salary package as well.
Here, you will also get the chance to obtain hidden facts concerning this subject.
Your every query will also get solved.
You will imbibe some latest trends, and features as well.
- Once you complete the MapReduce certification training program, you will become proficient in working with this phenomenal software framework/programming model. Furthermore, you will get a MapReduce training completion certificate. This will help you stand out from the rest of the candidates in front of recruiters and help you quickly get a job as a MapReduce expert/programmer in a good company.
- Advantages of getting certification:
You will find our every accreditation being extensively acknowledged in the industry.
Apart from technical courses, here at Croma Campus, you will get 140+ courses belonging to different sections.
Here, our trainers will not only impart information but will enhance your communication skills as well.
Our trainers will also make you aware of its relevant higher-level accreditation also.
By obtaining this certification, you will see positive growth in your career graph.
Why you should choose MapReduce Programmer certification?
By registering here, I agree to Croma Campus Terms & Conditions and Privacy Policy
 Course Duration
Course Duration
24 Hrs.
Flexible Batches For You

19-Apr-2025*
- Weekend
- SAT - SUN
- Mor | Aft | Eve - Slot

21-Apr-2025*
- Weekday
- MON - FRI
- Mor | Aft | Eve - Slot
-
16-Apr-2025*
- Weekday
- MON - FRI
- Mor | Aft | Eve - Slot
-
19-Apr-2025*
- Weekend
- SAT - SUN
- Mor | Aft | Eve - Slot
-
21-Apr-2025*
- Weekday
- MON - FRI
- Mor | Aft | Eve - Slot
-
16-Apr-2025*
- Weekday
- MON - FRI
- Mor | Aft | Eve - Slot
Course Price :
Want To Know More About
This Course
Program fees are indicative only* Know moreTimings Doesn't Suit You ?
We can set up a batch at your convenient time.
Program Core Credentials
Trainer Profiles
Industry Experts
Trained Students
10000+
Success Ratio
100%
Corporate Training
For India & Abroad
Job Assistance
100%
Batch Request
FOR QUERIES, FEEDBACK OR ASSISTANCE
Contact Croma Campus Learner Support
Best of support with us
CURRICULUM & PROJECTS
MapReduce Certification Training
- Apache PIG Framework
- Apache Spark with Scala Framework
- Apache HIVE Framework
- Apache SQOOP Framework
- Apache Hbase Framework
- Apache Flume Framework
- Apache Drill Framework
- Apache Kafka Framework
- Apache Storm Framework
- Introduction
- PIG Architecture
- Data Models, Operators, and Streaming in PIG
- Functions in PIG
- Advanced Concepts in PIG
- Big Data Overview
- Apache Hadoop Overview
- Hadoop Distribution File System
- Hadoop MapReduce Overview
- Introduction to PIG
- Prerequisites for Apache PIG
- Exploring use cases for PIG
- History of Apache PIG
- Why you need PIG
- Significance of PIG
- PIG over MapReduce
- When PIG suits the most
- When to avoid PIG
- PIG Latin Language
- Running PIG in Different Modes
- PIG Architecture
- GRUNT Shell
- PIG Latin Statements
- Running Pig Scripts
- Utility Commands
- PIG Data Model- Scalar Data type
- PIG Data Model - Complex Data Type
- Arithmetic Operators
- Comparison Operators
- Cast Operators
- Type Construction Operator
- Relational Operators
- Loading and Storing Operators
- Filtering Operators
- Filtering Operators-Pig Streaming with Python
- Grouping and Joining Operators-
- Sorting Operator
- Combining and Splitting Operators
- Diagnostic Operators
- Eval Functions
- Load and Store Functions
- Tuple and Bag Functions
- String Functions
- Math Function
- File compression in PIG
- Intermediate Compression
- Pig Unit Testing
- Embedded PIG in JAVA
- Pig Macros
- Import Macros
- Parameter Substitutions
- Introduction
- Scala
- Using Resilient Distributed Datasets
- Spark SQL, Data Frames, and Data Sets
- Running Spark on a cluster
- Machine Learning with Spark ML
- Spark Streaming
- Graph X
- Big Data Overview
- Apache Hadoop Overview
- Hadoop Distribution File System
- Hadoop MapReduce Overview
- Introduction to IntelliJ and Scala
- Installing IntelliJ and Scala
- Apache Spark Overview
- What’s new in Apache Spark 3
- Scala Basics
- Flow control in Scala
- Functions in Scala
- Data Structures in Scala
- The Resilient Distributed Dataset
- Ratings Histogram Example
- Key / Value RDD's, and the Average Friends by Age example
- Filtering RDD's, and the Minimum Temperature by Location Example
- Check Your Results and Implementation Against Mine
- Introduction to Spark SQL
- What are Data Frames
- What are Data Sets
- Item-Based Collaborative Filtering in Spark, cache (), and persist ()
- What is a Cluster
- Cluster management in Hadoop
- Introducing Amazing Elastic MapReduce
- Partitioning Concepts
- Troubleshooting and managing dependencies
- Introducing MLLib
- Using MLLib
- Linear Regression with MLLib
- Spark Streaming
- The DStream API for Spark Streaming
- Structured Streaming
- What is Graph X
- About Pregel
- Breadth-First-Search with Pregel
- Using Pregel API with Spark API
- Introduction
- Installing and Configuring HIVE
- Working on HIVE
- HIVE Implementation
- Big Data Overview
- Hadoop Overview
- What is a Hadoop Framework
- Types of Hadoop Frameworks
- What is Hive
- Motivation Behind the Tool
- Hive use cases
- Hive Architecture
- Different Modes of HIVE
- Downloading, installing, and configuring HIVE
- Hive Shell Commands
- Different configuration properties in HIVE
- Beeswax
- Installing and configuring MySQL Database
- Installing Hive Server
- Databases in Hive
- Datatypes in Hive
- Schema on Read
- Schema on Write
- Download Datasets
- Internal Tables
- External Tables
- Partition in HIVE
- Bucketing in HIVE
- Hive in Real Time Projects
- Auditing in Hive
- Troubleshooting Infra issues in Hive
- Troubleshooting User issues in Hive
- Hadoop Overview
- Sqoop Overview
- Sqoop Import
- Sqoop Export
- Career Guidance and Roadmap
- Course overview
- Big Data Overview
- Hadoop Overview
- HDFS
- YARN Cluster Overview
- Cluster Setup on Google Cloud
- Environment Update
- Sqoop Introduction
- Why Sqoop
- Sqoop Features
- Flume vs Sqoop
- Sqoop Architecture & Working
- Sqoop Commands.
- Managing Target Directories
- Working with Parquet File Format
- Working with Avro File Format
- Working with Different Compressions
- Conditional Imports
- Split-by and Boundary Queries
- Field delimiters
- Incremental Appends
- Sqoop Hive Import
- Sqoop List Tables/Database
- Export from HDFS to MySQL
- Export from Hive to MySQL
- Export Avro Compressed to MySQL
- Sqoop with Airflow
- Hadoop Overview
- No SQL Databases HBase
- Administration in HBASE
- Troubleshooting in HBASE
- Tuning in HBASE
- Apache HBase Operations Continuity
- Apache HBASE Ecosystem
- Career Guidance and Roadmap
- Course overview
- Big Data Overview
- Hadoop Overview
- HDFS
- Hadoop Ecosystem
- What is a Hadoop Framework
- Types of Hadoop frameworks
- NoSQL Databases HBase
- NoSQL Introduction
- HBase Overview
- HBase Architecture
- Data Model
- Connecting to HBase
- HBase Shell
- Introduction
- Learn and Understand HBase Fault Tolerance
- Hardware Recommendations
- Software Recommendations
- HBase Deployment at Scale
- Installation with Cloudera Manager
- Basic Static Configuration
- Rolling Restarts and Upgrades
- Interacting with HBase
- Introduction
- Troubleshooting Distributed Clusters
- Learn How to Use the HBase UI
- Learn How to Use the Metrics
- Learn How to Use the Logs
- Introduction
- Generating Load & Load Test Tool
- Generating With YCSB
- Region Tuning
- Table Storage Tuning
- Memory Tuning
- Tuning with Failures
- Tuning for Modern Hardware
- Introduction
- Corruption: hbck
- Corruption: Other Tools
- Security
- Security Demo
- Snapshots
- Import, Export and Copy Table
- Cluster Replication
- Introduction
- Hue
- HBase With Apache Phoenix’
- Apache Flume Overview
- Setting up Agents
- Configuring A Multi Agent Flow
- Flume Sinks
- Flume Channels
- Flume Sink Processors
- Flume Interceptors
- Security
- Career Guidance and Roadmap
- Course overview
- Big Data Overview
- Hadoop Overview
- HDFS
- Hadoop Ecosystem
- What is a Hadoop Framework
- Types of Hadoop frameworks
- Flume Overview
- Architecture
- Data flow mode
- Reliability and Recoverability
- Setting up an individual agent
- Configuring individual components
- Wiring the pieces together
- Data ingestion
- Executing Commands
- Network streams
- Setting Multi-Agent Flow
- Consolidation
- Multiplexing the flow
- Configuration
- Defining the flow
- Configuring individual components
- Adding multiple flows in an agent
- Fan out flow
- Flume Sources
- Avro Source, Exec Source
- NetCat Source
- Sequence Generator Source
- Syslog Sources
- Syslog TCP Source
- Syslog UDP Source
- Legacy Sources
- Avro Legacy Source
- Thrift Legacy Source
- Custom Source
- HDFS Sink
- Logger Sink
- Avro Sink
- IRC Sink
- File Roll Sink
- Null Sink
- HbaseSinks
- HbaseSink
- AsyncHBaseSink
- Custom Sink
- Memory Channel
- JDBC Channel
- Recoverable Memory Channel
- File Channel, Pseudo Transaction Channel
- Custom Channel
- Flume Channel Selectors
- Replicating Channel Selector
- Multiplexing Channel Selector
- Custom Channel Selector
- Default Sink Processor
- Failover Sink Processor
- Load balancing Sink Processor
- Custom Sink Processor
- Timestamp Interceptor
- Host Interceptor
- Flume Properties
- Property
- Monitoring
- Troubleshooting
- Handling agent failures
- Compatibility
- HDFS
- AVRO
- Apache Drill Overview
- Installing & Configuring Drill
- Querying Simple Delimited Data
- Configuration Options
- Understanding Data Types and Functions in Drill
- Working with Dates and Times in Drill
- Analyzing Nested Data with Drill
- Other Data Types
- Connecting Multiple Data Sources and programming languages
- Career Guidance and Roadmap
- Course overview
- Big Data Overview
- Hadoop Overview
- HDFS
- Hadoop Ecosystem
- What is a Hadoop Framework
- Types of Hadoop frameworks
- Drill Overview
- What does Drill do
- How does Drill work
- Kinds of data which can be queried with Drill
- Comparison of embedded and distributed modes
- Introducing and configuring workspaces
- Demonstrate Drill’s various interfaces
- SQL fundamentals
- Querying a simple CSV file
- Arrays in Drill
- Accessing columns in Arrays
- Extracting headers from csv files
- Changing delimiter characters
- Specifying options in a query
- Overview of Drill Data Types
- Converting Strings to Numeric Data Types
- Complex Conversions
- Windowing functions
- Understanding dates and times in Drill
- Converting strings to dates
- Reformatting dates
- Intervals and date/time arithmetic in Drill
- Issues querying nested data with Drill
- Maps and Arrays in Drill
- Querying deeply nested data in Drill
- Log files
- HTTPD
+ More Lessons
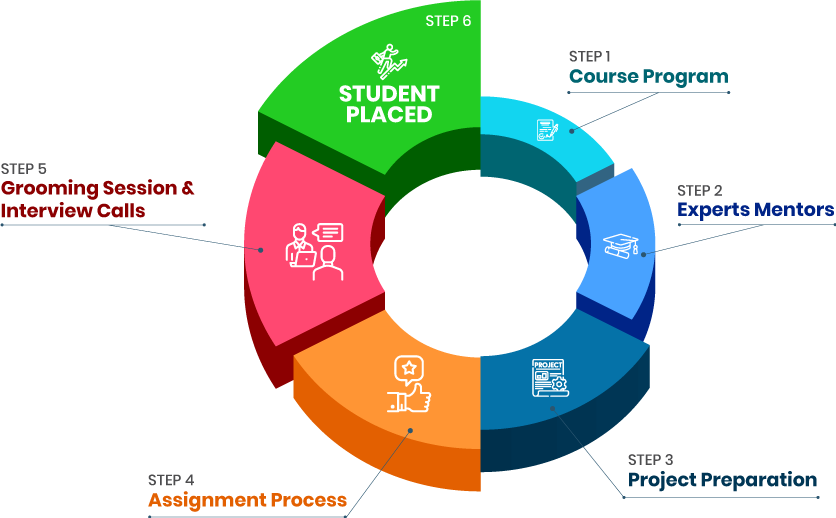
Mock Interviews
Phone (For Voice Call):
+91-971 152 6942WhatsApp (For Call & Chat):
+919711526942SELF ASSESSMENT
Learn, Grow & Test your skill with Online Assessment Exam to
achieve your Certification Goals

FAQ's
It basically counts the words in each document (map phase), while in the reduce phase it accumulates the data as per the document spanning the entire gathering. Eventually, during the map phase, the input data is divided into splits for analysis by map tasks executing in parallel across the Hadoop framework.
NameNode in Hadoop refers to the node where Hadoop stores all the file location information in HDFS (Hadoop Distributed File System) securely. If you want to acquire its detailed analysis, then you should get started with its professional course.
Yes, it's pretty much in demand, and in the coming years as well, it will remain consistently in use. So, if you possess your interest in this line, then you should acquire its accreditation, and make a career out of it.
Yes, we will provide you with the study material. In fact, you can also use our LMS portal and get extra notes, and class recordings as well.

- - Build an Impressive Resume
- - Get Tips from Trainer to Clear Interviews
- - Attend Mock-Up Interviews with Experts
- - Get Interviews & Get Hired
If yes, Register today and get impeccable Learning Solutions!

Training Features
Instructor-led Sessions
The most traditional way to learn with increased visibility,monitoring and control over learners with ease to learn at any time from internet-connected devices.
Real-life Case Studies
Case studies based on top industry frameworks help you to relate your learning with real-time based industry solutions.
Assignment
Adding the scope of improvement and fostering the analytical abilities and skills through the perfect piece of academic work.
Lifetime Access
Get Unlimited access of the course throughout the life providing the freedom to learn at your own pace.
24 x 7 Expert Support
With no limits to learn and in-depth vision from all-time available support to resolve all your queries related to the course.
Certification
Each certification associated with the program is affiliated with the top universities providing edge to gain epitome in the course.
Showcase your Course Completion Certificate to Recruiters
-
 Training Certificate is Govern By 12 Global Associations.
Training Certificate is Govern By 12 Global Associations.
-
Training Certificate is Powered by “Wipro DICE ID”
-
Training Certificate is Powered by "Verifiable Skill Credentials"



.webp)







WHAT OUR ALUMNI SAYS ABOUT US

Sachin Tyagi
Big Data HadoopThanks for making this wonderful platform available. I would love to encourage more people to join Croma Learning Campus to fill the gap for their career needs. I took Big Data Hadoop Training from Croma and I must say that course content is just the great and well-structured as per the certificatio Read more...

















 Master in Cloud Computing Training
Master in Cloud Computing Training