Master Spark ecosystem and Scala. Enroll now to learn from a Spark and Scala expert.
Course Duration
24 Hrs.Live Project
2 ProjectCertification Pass
GuaranteedTraining Format
Live Online /Self-Paced/ClassroomWatch Live Classes

Speciality
250+
Professionals Trained4+
Batches every month20+
Countries & Counting100+
Corporate Served- Croma Campus' Apache Spark training course has been thoroughly reviewed by industry professionals to ensure that it meets industry standards. This article will show you how to use Apache Spark and the Spark Ecosystem, which includes Spark RDD, Spark SQL, and Spark MLlib.
- Things you will learn:
- The Apache Spark certification training course will teach you all you need to know. It provides a basic Spark vs. Hadoop comparison.
You'll gain a thorough understanding of key Apache Spark principles.
Interact with and learn from your instructor as well as your classmates.
How to build Spark apps using Scala programming.
how to increase application performance and enable high-speed processing using Spark RDDs
You'll learn how to customise Spark using Scala in this course.
Apache Spark and Scala Training


- Whether you're a beginner or a seasoned veteran, our Apache Spark training course will help you grasp all of the principles and put them into practise at work. Let's talk about the course goals:
Be familiar with Big Data, its components and frameworks, as well as Hadoop Cluster design and modes.
Know how to programme in Scala, how to implement it, and how to use the core Apache Spark constructs.
Gain an understanding of Apache Spark concepts and learn how to build Spark apps.
Understand the Apache Spark framework's concepts and deployment procedures.
Learn how to use the Spark Internals RDD, as well as the Spark API and Scala functions, to create and modify RDDs.
Be an expert in SparkSQL, Spark Context, Spark Streaming, MLlib, and GraphX, as well as RDD and other Combiners.
- The company where you work will also determine your income. Pay for businesses such as Cognizant, Accenture, and Infosys is normally good, but you may make a lot of money working for Amazon, Microsoft, or Yahoo.
A Spark developer at the beginning level can expect to earn between Rs 6,00,000 and Rs 10,00,000 per year.
A skilled developer might make anywhere between Rs 25,00,000 and Rs 40,00,000.
A Data Engineer with Apache Spark expertise may expect to earn more than Rs 10,00,000 per year on average.
You will receive a greater wage package after completing your Apache Spark certification course.
A Data Scientist with Apache Spark skills in Hyderabad, on the other hand, may earn more than Rs 8,00,000 per year on average.
- If you want to break into the big data industry and succeed, Apache Spark is the way to go, as it offers a wide range of options for big data analysis. It is the most popular Big Data technology because its different approaches are effective against a variety of data difficulties.
- That’s the reason, there’s a huge demand for Apache Spark training courses among students.
Because Spark can operate on Hadoop MapReduce, YARN, and HDFS, it outperforms Hadoop.
Because of its great Hadoop compatibility, companies are looking for a big number of Spark Developers.
Many companies are turning to Spark as a complementary big data platform since it processes data much quicker than Hadoop.
As technology progresses and new businesses turn to big data management to fulfil their needs, a plethora of new options emerge.
- Today, there are opportunities all around the world, including in India, resulting in a growth in professional opportunities for skilled persons.
Companies all across the world are using Spark as their primary big data processing platform.
You'll have the opportunity to work in a range of fields, including retail, software, media and entertainment, consulting, healthcare, and more.
To gain a competitive advantage, every industry is employing big data analytics and machine learning techniques.
- You will be required to undertake a variety of work duties and responsibilities after completing your Apache Spark training course.
Ability to define problems, collect data, establish facts, and draw valid conclusions using software code.
Using Spark, produce ready-to-use data by cleaning, processing, and analysing raw data from different mediation sources.
To guarantee that joins are executed quickly, refactoring code is utilised.
Assist with the Spark platform's technical architecture.
Use partitioning strategies to meet certain use situations.
Hold deep-dive working sessions to fix Spark platform issues fast.
- Top Hiring Industries in Apache Spark:
Google, Cognizant Technology Solutions, TCS, IBM, Accenture, and other well-known employers.
In addition, we have a team of experts who can assist you with resume writing and interview preparation.
You will have the opportunity to participate in interviews and be hired in a variety of industries.
There are several work opportunities available all over the world.
- Training Certificate:
With our certification, you may be able to work from anywhere.
In today's tech-driven environment, you'll be more valuable.
Our certification could help you outperform the competition.
Make a name for yourself as a sought-after expert.
Obtain a sizable remuneration package.
Why Should You Learn Apache Spark Training?
By registering here, I agree to Croma Campus Terms & Conditions and Privacy Policy
 Course Duration
Course Duration
24 Hrs.
Flexible Batches For You

19-Apr-2025*
- Weekend
- SAT - SUN
- Mor | Aft | Eve - Slot

21-Apr-2025*
- Weekday
- MON - FRI
- Mor | Aft | Eve - Slot
-
16-Apr-2025*
- Weekday
- MON - FRI
- Mor | Aft | Eve - Slot
-
19-Apr-2025*
- Weekend
- SAT - SUN
- Mor | Aft | Eve - Slot
-
21-Apr-2025*
- Weekday
- MON - FRI
- Mor | Aft | Eve - Slot
-
16-Apr-2025*
- Weekday
- MON - FRI
- Mor | Aft | Eve - Slot
Course Price :
Want To Know More About
This Course
Program fees are indicative only* Know moreTimings Doesn't Suit You ?
We can set up a batch at your convenient time.
Program Core Credentials
Trainer Profiles
Industry Experts
Trained Students
10000+
Success Ratio
100%
Corporate Training
For India & Abroad
Job Assistance
100%
Batch Request
FOR QUERIES, FEEDBACK OR ASSISTANCE
Contact Croma Campus Learner Support
Best of support with us
CURRICULUM & PROJECTS
Apache Spark and Scala Training
- Introduction
- Scala
- Using Resilient Distributed Datasets
- Spark SQL, Data Frames, and Data Sets
- Running Spark on a cluster
- Machine Learning with Spark ML
- Spark Streaming
- Graph X
- Overview
- Kafka Producer
- Kafka Consumers
- Kafka Internals
- Cluster Architecture and Administering Kafka
- Kafka Monitoring & Kafka Connect
- Kafka Stream Processing
- Kafka Integration with Hadoop, Storm, and Spark
- Kafka Integration with Flume, Talend and Cassandra
- Career Guidance and Roadmap
- Introduction
- PIG Architecture
- Data Models, Operators, and Streaming in PIG
- Functions in PIG
- Advanced Concepts in PIG
- Hadoop Overview
- No SQL Databases Hbase
- Administration in HBASE
- Troubleshooting in Hbase
- Troubleshooting in Hbase
- Troubleshooting in Hbase
- Apache HBASE Ecosystem
- Big Data Overview
- Apache Hadoop Overview
- Hadoop Distibution File System
- Hadoop MapReduce Overview
- Introduction to IntelliJ and Scala
- Installing IntelliJ and Scala
- Apache Spark Overview
- What’s new in Apache Spark 3
- Flow control in Scala
- Functions in Scala
- Data Structures in Scala
- The Resilient Distributed Dataset
- Ratings Histogram Example
- Key/value RDD's and the Average Friends by Age example
- Filtering RDD's and the Minimun Temperature by Location Example
- Check Your Results and Implementation Against Min
- Introduction to Spark SQL
- What are Data Frames
- What are Data Sets
- Item-Based Collaborative Filtering in Spark, cache (), and persist ()
- What is a Cluster
- Cluster management in Hadoop
- Introducing Amazing Elastic MapReduce
- Partitioning Concepts
- Troubleshooting and managing dependencies
- Introduction MLLib
- Using MLLib
- Linear Regression with MLLib
- Spark Streaming
- The DStream API for Spark Streaming
- What is Graph X
- About Pregel
- Breadth-First-Search with Pregel
- Using Pregel API with Spark API
- Introduction to Big Data
- Big Data Analytics
- Need for Kafka
- What is Kafka
- Kafka Features
- Kafka Concepts
- Kafka Architecture
- Kafka Components
- Zookeeper
- Where is Kafka Used
- Kafka Installation
- Kafka Cluster
- Type of Kafka Clusters
- Configuring Single Node Single Broker Cluster
- Configuring Single Node Multi Broker Cluster
- Sending a Message to Kafka
- Producing Keyed and Non-Keyed Messages
- Sending a Message Synchronously & Asynchronously
- Configuring Producers
- Serializers
- Serializing Using Apache Avro
- Partitions
- Consumers and Consumer Groups
- Standalone Consumer
- Consumer Groups and Partition Rebalance
- Creating a Kafka Consumer
- Subscribing to Topics
- The Poll Loop
- Configuring Consumers
- Commits and Offsets
- Rebalance Listeners
- Consuming Records With Specific Offsets
- De-serializers
- Cluster Membership
- The Controller
- Replication
- Request Processing
- Physical Storage
- Reliability
- Broker Configuration
- Using Producers in a Reliable System
- Using Consumers in a Reliable System
- Validating System Reliability
- Performance Tuning in Kafka
- Use Cases - Cross-Cluster Mirroring
- Multi-Cluster Architectures
- Apache Kafka’s Mirror Maker
- Other Cross-Cluster Mirroring Solutions
- Topic Operations
- Consumer Groups
- Dynamic Configuration Changes
- Partition Management
- Consuming and Producing
- Unsafe Operations
- Considerations When Building Data Pipelines
- Metric Basics
- Kafka Broker Metrics
- Client Monitoring
- Lag Monitoring
- End-to-End Monitoring
- Kafka Connect
- When to Use Kafka Connect
- Kafka Connect Properties
- Stream Processing
- Stream-Processing Concepts
- Stream-Processing Design Patterns
- Kafka Streams by Example
- Kafka Streams: Architecture Overview
- Apache Hadoop Basics
- Hadoop Configuration
- Kafka Integration with Hadoop
- Apache Storm Basics
- Configuration of Storm
- Integration of Kafka with Storm
- Apache Spark Basics
- Spark Configuration
- Kafka Integration with Spark
- Flume Basics
- Integration of Kafka with Flume
- Cassandra Basics Such as Key Space and Table Creation
- Integration of Kafka with Cassandra
- Talend Basics
- Integration of Kafka with Talend
- Apache Hadoop Overview
- Hadoop Distribution File System
- Hadoop MapReduce Overview
- Introduction to PIG
- Prerequisites for Apache PIG
- Exploring use cases for PIG
- History of Apache PIG
- Why you need PIG
- Significance od PIG
- PIG over MapReduce
- When PIG suits the most
- When to avoid PIG
- PIG Latin Language
- Running PIG in Different Modes
- PIG Architecture
- GRUNT Shell
- PIG Latin Statements
- Running Pig Scripts
- Utility Commands
- PIG Data Model - Scarlar Data Type
- PIG Data Model - Complex Data Type
- Arithmetic Operators
- Comparison Operators
- Cast Operators
- Type Construction Operators
- Relation Operators
- Loading and Stroing Operators
- Filtering Operators
- Filtering Operators- Pig Streaming with Python
- Grouping and Joining Operators-
- Sorting Operator
- Combining and Splitting Operators
- Diagnostic Operators
- Eval Functions
- Load and Store Funtions
- Tuple and Bag Functions
- String Functions
- Math Function
- File compression in PIG
- Intermediate Compression
- Pig Unit Testing
- Embedded PIG in JAVA
- Pig Macros
- Import Macros
- Parameter Substitutions
- Course overview
- Big Data Overview
- Hadoop Overview
- HDFS
- Hadoop Ecosystem
- What is a Hadoop Framework
- Type of Hadoop Frameworks
- NoSQL Databases Hbase
- NoSQL Introduction
- HBase Overview
- HBase Architecture
- Data Model
- Connecting to HBase
- HBase Shell
- Introduction
- Learn and Understand Hbase Fault Tolerance
- Hardware Recommendations
- Software Recommendations
- Hbase Deployment at scale
- Installation with Cloudera Manager
- Basic Static Configuration
- Rolling Restarts and Upgrades
- Interacting with HBase
- Introduction
- Troubleshooting Distributed Clusters
- Learn How To Use the Hbase UI
- Learn How To Use the Metrics
- Learn How To Use the Logs
- Introduction
- Generating Load & Load Test Tool
- Generating With YCSB
- Region Tuning
- Table Storage Tuning
- Memory Tuning
- Tuning with Failures
- Tuning for Modern Hardware
- Introduction
- Corruption: hbck
- Corruption: Other Tools
- Security
- Security Demo
- Snapshots
- Import Export and copy Paste
- Cluster Replication
- Introduction
- Hue
- HBase With Apache Phoenix’
+ More Lessons
Mock Interviews
Phone (For Voice Call):
+91-971 152 6942WhatsApp (For Call & Chat):
+919711526942SELF ASSESSMENT
Learn, Grow & Test your skill with Online Assessment Exam to
achieve your Certification Goals

FAQ's
Pre-course reading will be provided so that you are familiar with the content before the class begins.
Yes. Visit our payment plans website to discover more about the payment choices available at Croma Campus.
You will be able to register for our next training session, as we only offer two to three each year.
Yes, there are a variety of payment options.

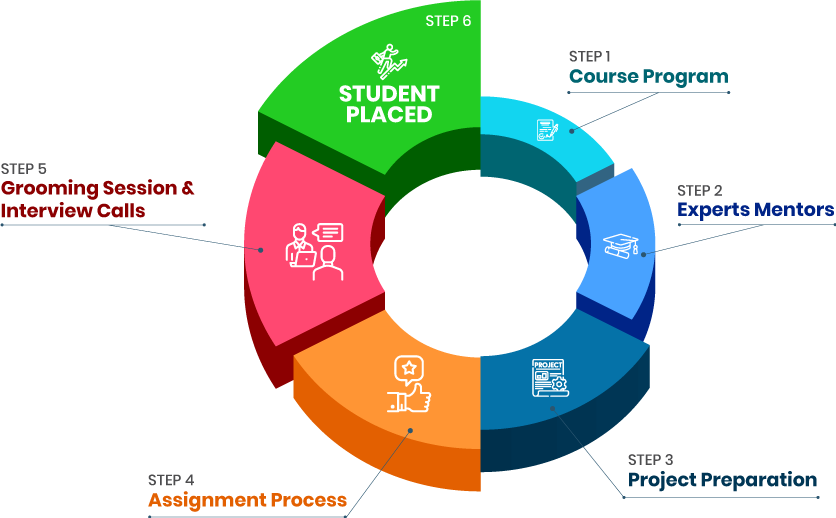
- - Build an Impressive Resume
- - Get Tips from Trainer to Clear Interviews
- - Attend Mock-Up Interviews with Experts
- - Get Interviews & Get Hired
If yes, Register today and get impeccable Learning Solutions!

Training Features
Instructor-led Sessions
The most traditional way to learn with increased visibility,monitoring and control over learners with ease to learn at any time from internet-connected devices.
Real-life Case Studies
Case studies based on top industry frameworks help you to relate your learning with real-time based industry solutions.
Assignment
Adding the scope of improvement and fostering the analytical abilities and skills through the perfect piece of academic work.
Lifetime Access
Get Unlimited access of the course throughout the life providing the freedom to learn at your own pace.
24 x 7 Expert Support
With no limits to learn and in-depth vision from all-time available support to resolve all your queries related to the course.
Certification
Each certification associated with the program is affiliated with the top universities providing edge to gain epitome in the course.
Showcase your Course Completion Certificate to Recruiters
-
 Training Certificate is Govern By 12 Global Associations.
Training Certificate is Govern By 12 Global Associations.
-
Training Certificate is Powered by “Wipro DICE ID”
-
Training Certificate is Powered by "Verifiable Skill Credentials"



.webp)







WHAT OUR ALUMNI SAYS ABOUT US

Sachin Tyagi
Big Data HadoopThanks for making this wonderful platform available. I would love to encourage more people to join Croma Learning Campus to fill the gap for their career needs. I took Big Data Hadoop Training from Croma and I must say that course content is just the great and well-structured as per the certificatio Read more...
















 Master in Cloud Computing Training
Master in Cloud Computing Training